M. Stöcklin
Was ist maschinelles Lernen und wie es funktioniert.
Maschinelles Lernen ist eine Methode der Datenanalyse, die die Erstellung von analytischen Modellen automatisiert.

Es ist ein Zweig der künstlichen Intelligenz, der auf der Idee basiert, dass Systeme von Daten lernen, Muster erkennen und Entscheidungen mit minimalem menschlichem Eingriff treffen können.
Tatsächlich gibt es unterschiedliche Varianten von Lernalgorithmen, so können diese nach deren Lernweise (d.h. beaufsichtigtes Lernen, unbeaufsichtigtes Lernen, semi-beaufsichtigtes Lernen) oder nach Ähnlichkeit in Form oder Funktion (d.h. Klassifizierung, Regression, Entscheidungsbaum, Clustering, Deep Learning usw.) unterschieden werden. Unabhängig vom Lernstil basieren die Algorithmischen Grundlagen jedoch immer auf einer ähnlichen Vorgehensweise.
- Repräsentation
(eine Reihe von Klassifizierern oder die Sprache, die ein Computer versteht) - Bewertung
(Ziel / Bewertungsfunktion) - Optimierung
(Suchmethode; häufig zum Beispiel der Klassifikator mit der höchsten Bewertung; es werden sowohl standardmäßige als auch benutzerdefinierte Optimierungsmethoden verwendet)
In diesem Artikel erläutere ich die Komponente der Repräsentation, die weiteren Methoden werden in einer Fortsetzung aufgegriffen.
Repräsentation
Ich gehe nicht auf alle Formen einer Repräsentation ein, werde aber die aus meiner Sicht wichtigsten Verfahren kurz erläutern.
Ein Repräsenationsmodell ist der Entscheidungsbaum (wenn, dann).
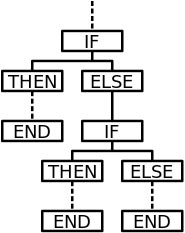
Dies ist aus meiner Sicht die einfachste Form eines "intelligenten Systems", dabei wird der Enscheidungsablauf durch das Wissen eines oder mehrerer Experten vorgegeben. Durch geeignete Fragestellungen oder diskrete Sensoren erfolgt somit ein definierter Ablauf innerhalb eines gerichteten Graphen bzw. Baumes. Die Ergebnisse sind somit jederzeit nachvollziehbar. Es gibt zwischenzeitlich auch Abwandlungen dieser binären Entscheidungsbäume, so bspw. die Erweiterung mit sogenannten Fuzzy-Sets, die eine Unschärfe zulassen und somit nicht zwangsläufig mit genau einem Ergebnis enden. Dabei wird wie bei der Wahrscheinlichkeit eine prozentuale Zugehörigkeit zu einer Lösungsmenge berechnet.
Ein weiteres Modell sind Neuronale Netze.
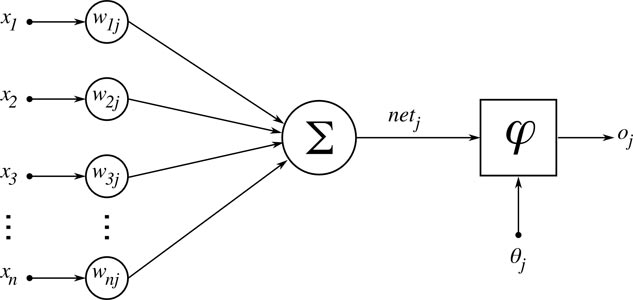
Diese orientieren sich am Vorbild der Natur und versuchen die Arbeitsweise stark vereinfacht nachzubilden. Dabei werden Neuronen durch einen Input angeregt und führen bei bestimmten Aktivierungswerten zu einem Output. Im Gegensatz zu einem Entscheidungsbaum, werden die Aktivierungsfunktionen bzw. deren Parameter nicht vorgegeben, sondern in einer Lernphase - abhängig vom verwendeten Modell des neuronalen Netzes - automatisch gesetzt, bspw. durch eine Lernregel die den Input und erwarteten Output vergleicht (überwachtes Lernen). Darüber hinaus gibt es Abwandlungen die auch ein unbeaufsichtiges Lernen oder Zwischenstufen abbilden.
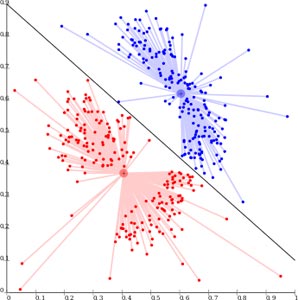
Clustering ist eine Technik des Machine Learning, bei der Datenpunkte gruppiert werden.
{kind=link}
In den letzten Jahren wurde diese Repräsentation sehr stark im Umfeld von Data-Mining eingesetzt, um Zusammenhänge in großen Datenmengen zu finden. Dabei wird versucht einzelne Datenpunkte in eine bestimmte Gruppe zu klassifizieren. Theoretisch sollten Datenpunkte, die sich in derselben Gruppe befinden, ähnliche Eigenschaften und/oder Merkmale aufweisen, während Datenpunkte in verschiedenen Gruppen sehr unterschiedliche Eigenschaften und/oder Merkmale aufweisen sollten. Ziel ist es aber nicht nur divergente Gruppen zu finden, sondern natürlich insbesondere die Merkmale zu kennen, die diese Zugehörigkeit bestimmen.
Die Repräsentation findet häufg in einem n-dimensionalen Raum statt und somit liegt auch die Gruppierung in einem n-dimensionalen Raum, dies macht den Vorgang der Visualisierung natürlich komplex und wird daher auf 2 bzw. 3 Dimensionen abgebildet.
Die in der Wissenschaft bekanntesten Cluster Methoden sind:
- K-Means Clustering
- Mean-Shift Clustering
- Dichtebasiertes räumliches Clustering von Anwendungen mit Rauschen (DBSCAN)
- Erwartungsmaximierung (EM) Clustering mit Gaußschen Mischmodellen (GMM)
- Agglomeratives hierarchisches Clustering
Wird das Clustering mit Hilfe von Neuronalen Netzen (bspw. Kohonen Netzen) durchgeführt spricht man von unüberwachtem Lernen. Einige der Einsatzgebiete sind:
- Empfehlungssysteme
Wer x gekauft hat ist vermutlich auch an y interessiert. - Marktsegmentierung
Es sollen 5 Gruppen gebildet werden, welche Merkmale repräsentieren diese am Besten. - Analyse von sozialen Netzwerken
Welche Eigenschaften besitzen meine Freunde und welche Freunde meiner Freunde besitzen ähnliche Eigenschaften. - Gruppierung der Suchergebnisse
- Medizinische Bildgebung
- Bildsegmentierung
- Anomalieerkennung